Bayesian sampling of reflectometry models is a common tool in the analysis of specular reflectometry data. The Python programming language has a powerful infrastructure for this modelling, including packages such as PyMC3 and PyStan. Here, we will show how the emcee Python may be used to enable Bayesian sampling in BornAgain and the differential evoulation optimisation algorithm from the scipy.
To generate these images of the probability distributions of the parameters and the maximum likelihood reflectometry profile
run this script.
The system under investigation in the above example is a Ni-Ti multilayer material at the interface between an Si substrate and a vacuum.
There are two parameters of interest, the thicknesses of the Ni and Ti layers.
We know the scattering length densities for each, and that in total there are 10 repetitions of the Ni-Ti sandwich.
This sample is created in the get_sample function.
Having built the sample, it is necessary to obtain the real experimental data.
For the above code to work locally, the following data file is required and the Python script (in particular the get_real_data function) should be adapted appropriately.
This function defined an uncertainty in the reflectivity of 10 %.
The simulation is then defined in the get_simulation function, which is passed a series of angles, however, this may be modified to perform a Q-scan as necessary.
The final function that is necessary is the simulation of specular reflectometry is the run_simulation function.
This will take the angle-value to be simulated and thickness for the Ni and Ti layers and then return the result of the simulation as a numpy.array.
We will use the emcee package to sampling the likelihood of the data (we are follow their data fitting example).
Therefore, it is necessary to define a likelihood (the log_likelihood function) objective.
Then, within the main body of the scirpt we firstly find the maximum likelihood solution using a differential evolution algorithm from the scipy.optimize library.
This should print that then thicknesses are around 7 nm and 3 nm for the Ni and Ti respectively.
We can use the emcee.EnsembleSampler to probe the uncertainties in the parameters and there correlation.
This will perform the sampling for some time (on my machine it took about 2.5 minutes to sample 1000 steps with 32 walkers).
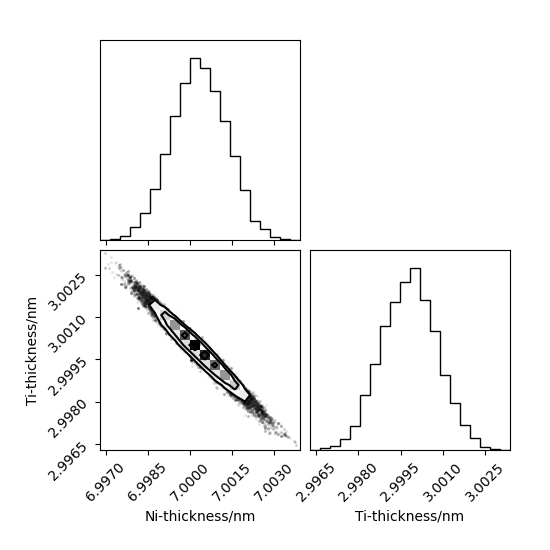
Having collected the samples, we can then unpack them and using the corner package visualise them.
This will give the first image shown above.
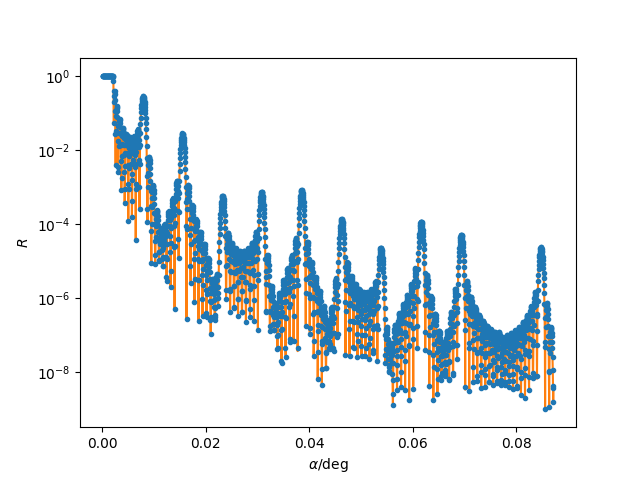
Finally, we can plot the maximum likelihood estimate for the model along with the experimental data. This is the second image above.
Note that the flat_samples object describes the distributions shown in the corner plot.
Therefore we can find values of interest, such as the standard deviation or confident intervals.